‘dynamic evaluation (NN)’ directory
- See Also
- Gwern
- Links
- “Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search”, Sokota et al 2025
- “The Hidden Drivers of HRM’s Performance on ARC-AGI”
- “New News: System-2 Fine-Tuning for Robust Integration of New Knowledge”, Park et al 2025
- “On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”, Lampinen et al 2025
- “One-Minute Video Generation With Test-Time Training”, Dalal et al 2025
- “RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”, Peng et al 2025
- “NVARC Solution”
- “AUNN: Simple Implementation of Gwern’s AUNN Proposal”, Roland 2024
- “The Surprising Effectiveness of Test-Time Training for Few-Shot Learning”, Akyürek et al 2024
- “Emergent Properties With Repeated Examples”, Charton & Kempe 2024
- “Evaluating the Fairness of Task-Adaptive Pretraining on Unlabeled Test Data Before Few-Shot Text Classification”, Dubey 2024
- “Learning to (Learn at Test Time): RNNs With Expressive Hidden States”, Sun et al 2024
- “Instruction Modeling: Instruction Tuning With Loss Over Instructions”, Shi et al 2024
- “Test-Time Augmentation to Solve ARC”, Cole 2024
- “An Accurate and Rapidly Calibrating Speech Neuroprosthesis”, Card et al 2024
- “Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”, Rannen-Triki et al 2024
- “Neural Spline Fields for Burst Image Fusion and Layer Separation”, Chugunov et al 2023
- “Test-Time Adaptation of Discriminative Models via Diffusion Generative Feedback”, Prabhudesai et al 2023
- “In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries”, Shi et al 2023
- “OSD: Online Speculative Decoding”, Liu et al 2023
- “Dynamic Evaluation”, Gwern 2023
- “Re2: Re-Reading Improves Reasoning in Large Language Models”, Xu et al 2023
- “Test-Time Training on Video Streams”, Wang et al 2023
- “TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”, Hardt & Sun 2023
- “FWL: Meta-Learning Fast Weight Language Models”, Clark et al 2022
- “Test-Time Training With Masked Autoencoders”, Gandelsman et al 2022
- “Large-Scale Retrieval for Reinforcement Learning”, Humphreys et al 2022
- “Don’t Stop the Training: Continuously-Updating Self-Supervised Algorithms Best Account for Auditory Responses in the Cortex”, Orhan et al 2022
- “Reconsidering the Past: Optimizing Hidden States in Language Models”, Yoshida & Gimpel 2021
- “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”, Lazaridou et al 2021
- “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”, Lazaridou et al 2021 (page 7 org deepmind)
- “Deep-Learning the Hardest Go Problem in the World (Igo #120)”, Wu 2019
- “Test-Time Training With Self-Supervision for Generalization under Distribution Shifts”, Sun et al 2019
- “Unsupervised Domain Adaptation through Self-Supervision”, Sun et al 2019
- “Mogrifier LSTM”, Melis et al 2019
- “Dynamic Evaluation of Transformer Language Models”, Krause et al 2019
- “Learning and Evaluating General Linguistic Intelligence”, Yogatama et al 2019
- “Faster SGD Training by Minibatch Persistency”, Fischetti et al 2018
- “Continuous Learning in a Hierarchical Multiscale Neural Network”, Wolf et al 2018
- “Dynamic Evaluation of Neural Sequence Models”, Krause et al 2017
- “Bayesian Recurrent Neural Networks”, Fortunato et al 2017
- “Learning Simpler Language Models With the Differential State Framework”, II et al 2017
- “Neural Episodic Control”, Pritzel et al 2017
- “Multiplicative LSTM for Sequence Modeling”, Krause et al 2016
- “One Sentence One Model for Neural Machine Translation”, Li et al 2016
- “Generating Sequences With Recurrent Neural Networks”, Graves 2013
- “Recurrent Neural Network Based Language Model § Dynamic Evaluation”, Mikolov et al 2010 (page 2)
- “Fast Text Compression With Neural Networks”, Mahoney 2000
- “OpenAI API § Prompt Caching”
- “RWKV Language Model”
- “Yu Sun”
- Sort By Magic
- Wikipedia (2)
- Miscellaneous
- Bibliography
See Also
Gwern
“Nenex: A Neural Personal Wiki Idea”, Gwern 2023
Links
“Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search”, Sokota et al 2025
Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search
“The Hidden Drivers of HRM’s Performance on ARC-AGI”
“New News: System-2 Fine-Tuning for Robust Integration of New Knowledge”, Park et al 2025
New News: System-2 Fine-tuning for Robust Integration of New Knowledge
“On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”, Lampinen et al 2025
On the generalization of language models from in-context learning and finetuning: a controlled study
“One-Minute Video Generation With Test-Time Training”, Dalal et al 2025
“RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”, Peng et al 2025
“NVARC Solution”
“AUNN: Simple Implementation of Gwern’s AUNN Proposal”, Roland 2024
“The Surprising Effectiveness of Test-Time Training for Few-Shot Learning”, Akyürek et al 2024
The Surprising Effectiveness of Test-Time Training for Few-Shot Learning
“Emergent Properties With Repeated Examples”, Charton & Kempe 2024
“Evaluating the Fairness of Task-Adaptive Pretraining on Unlabeled Test Data Before Few-Shot Text Classification”, Dubey 2024
“Learning to (Learn at Test Time): RNNs With Expressive Hidden States”, Sun et al 2024
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
“Instruction Modeling: Instruction Tuning With Loss Over Instructions”, Shi et al 2024
Instruction Modeling: Instruction Tuning With Loss Over Instructions
“Test-Time Augmentation to Solve ARC”, Cole 2024
“An Accurate and Rapidly Calibrating Speech Neuroprosthesis”, Card et al 2024
“Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”, Rannen-Triki et al 2024
Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models
“Neural Spline Fields for Burst Image Fusion and Layer Separation”, Chugunov et al 2023
Neural Spline Fields for Burst Image Fusion and Layer Separation
“Test-Time Adaptation of Discriminative Models via Diffusion Generative Feedback”, Prabhudesai et al 2023
Test-time Adaptation of Discriminative Models via Diffusion Generative Feedback
“In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries”, Shi et al 2023
In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries
“OSD: Online Speculative Decoding”, Liu et al 2023
“Dynamic Evaluation”, Gwern 2023
“Re2: Re-Reading Improves Reasoning in Large Language Models”, Xu et al 2023
“Test-Time Training on Video Streams”, Wang et al 2023
“TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”, Hardt & Sun 2023
TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models
“FWL: Meta-Learning Fast Weight Language Models”, Clark et al 2022
“Test-Time Training With Masked Autoencoders”, Gandelsman et al 2022
“Large-Scale Retrieval for Reinforcement Learning”, Humphreys et al 2022
“Don’t Stop the Training: Continuously-Updating Self-Supervised Algorithms Best Account for Auditory Responses in the Cortex”, Orhan et al 2022
“Reconsidering the Past: Optimizing Hidden States in Language Models”, Yoshida & Gimpel 2021
Reconsidering the Past: Optimizing Hidden States in Language Models
“Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”, Lazaridou et al 2021
Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling
“Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”, Lazaridou et al 2021 (page 7 org deepmind)
Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation
“Deep-Learning the Hardest Go Problem in the World (Igo #120)”, Wu 2019
Deep-Learning the Hardest Go Problem in the World (Igo #120)
“Test-Time Training With Self-Supervision for Generalization under Distribution Shifts”, Sun et al 2019
Test-Time Training with Self-Supervision for Generalization under Distribution Shifts
“Unsupervised Domain Adaptation through Self-Supervision”, Sun et al 2019
“Mogrifier LSTM”, Melis et al 2019
“Dynamic Evaluation of Transformer Language Models”, Krause et al 2019
“Learning and Evaluating General Linguistic Intelligence”, Yogatama et al 2019
“Faster SGD Training by Minibatch Persistency”, Fischetti et al 2018
“Continuous Learning in a Hierarchical Multiscale Neural Network”, Wolf et al 2018
Continuous Learning in a Hierarchical Multiscale Neural Network
“Dynamic Evaluation of Neural Sequence Models”, Krause et al 2017
“Bayesian Recurrent Neural Networks”, Fortunato et al 2017
“Learning Simpler Language Models With the Differential State Framework”, II et al 2017
Learning Simpler Language Models with the Differential State Framework
“Neural Episodic Control”, Pritzel et al 2017
“Multiplicative LSTM for Sequence Modeling”, Krause et al 2016
“One Sentence One Model for Neural Machine Translation”, Li et al 2016
“Generating Sequences With Recurrent Neural Networks”, Graves 2013
“Recurrent Neural Network Based Language Model § Dynamic Evaluation”, Mikolov et al 2010 (page 2)
Recurrent Neural Network Based Language Model § Dynamic Evaluation
“Fast Text Compression With Neural Networks”, Mahoney 2000
“OpenAI API § Prompt Caching”
“RWKV Language Model”
“Yu Sun”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
continuous-learning
reinforcement-strategies
test-time-training
dynamic-evaluation
Wikipedia (2)
Miscellaneous
/doc/ai/nn/dynamic-evaluation/2023-hardt-figure7-bitesperbyteforgpt2large.jpg/doc/ai/nn/dynamic-evaluation/2023-hardt-figure8-bitesperbyteforgptneo.jpghttps://benkrause.github.io/blog/human-level-text-prediction/https://www.latent.space/p/fastai#%C2%A7replacing-fine-tuning-with-continued-pre-training
{kind=link}
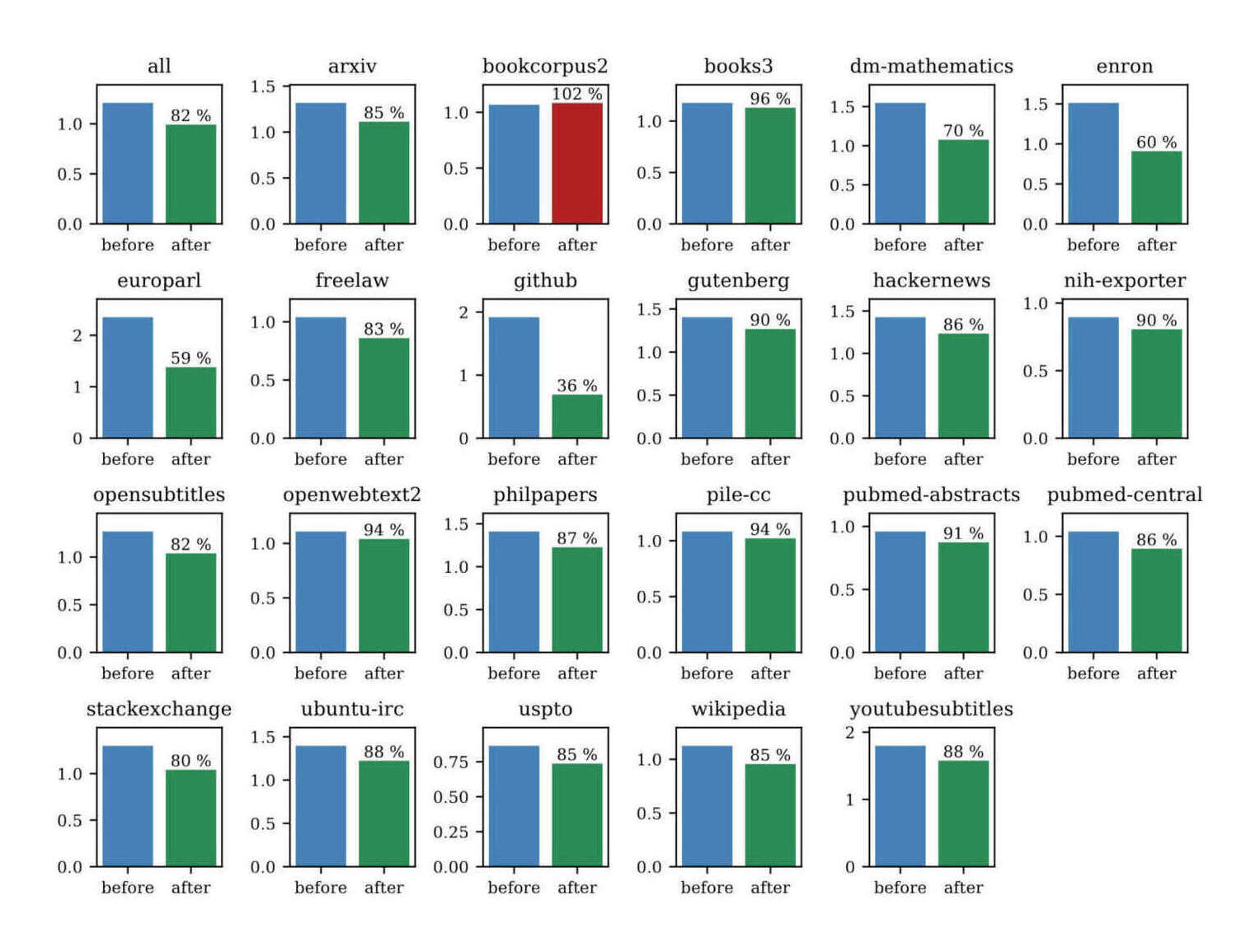{kind=link}
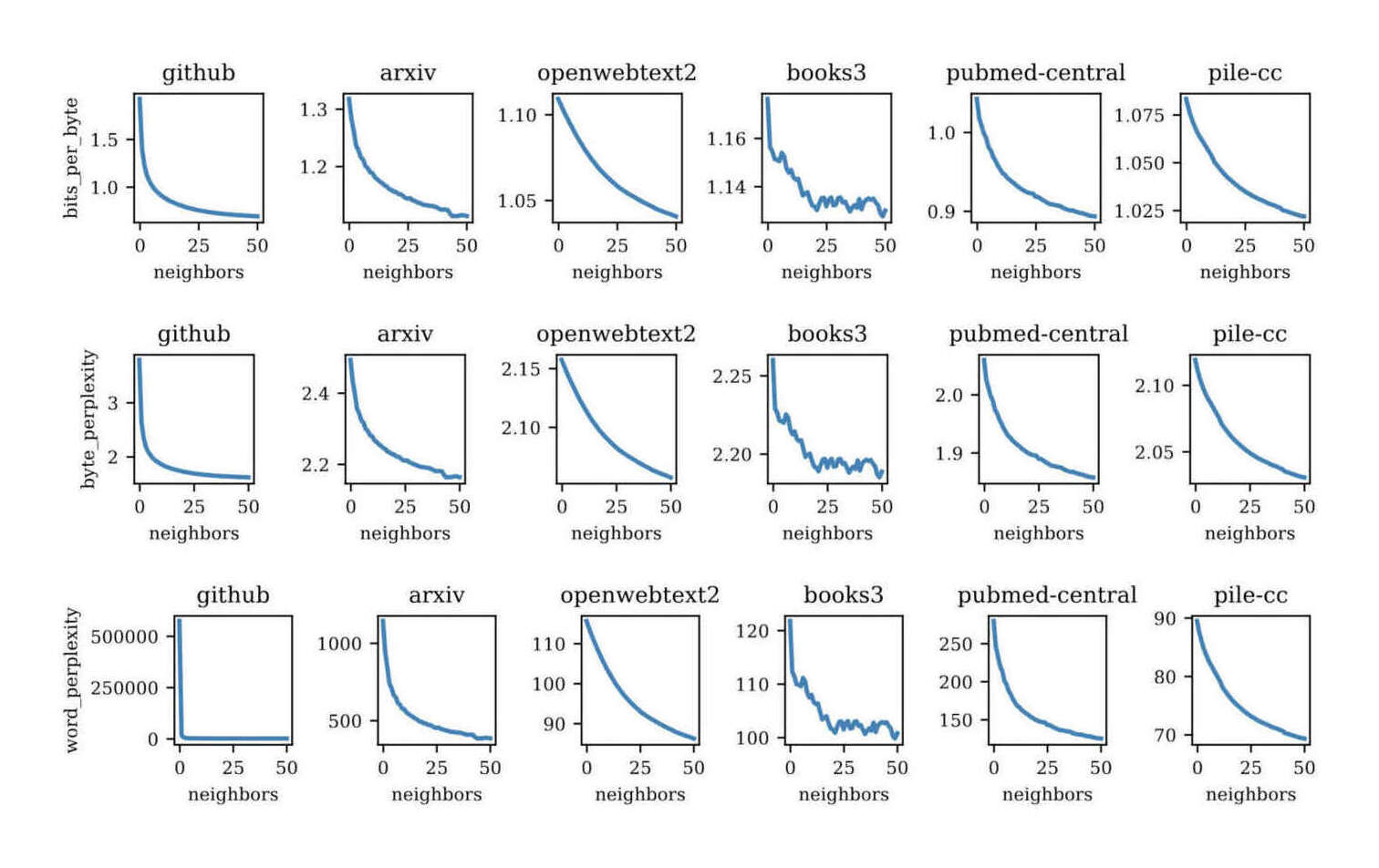{kind=link}
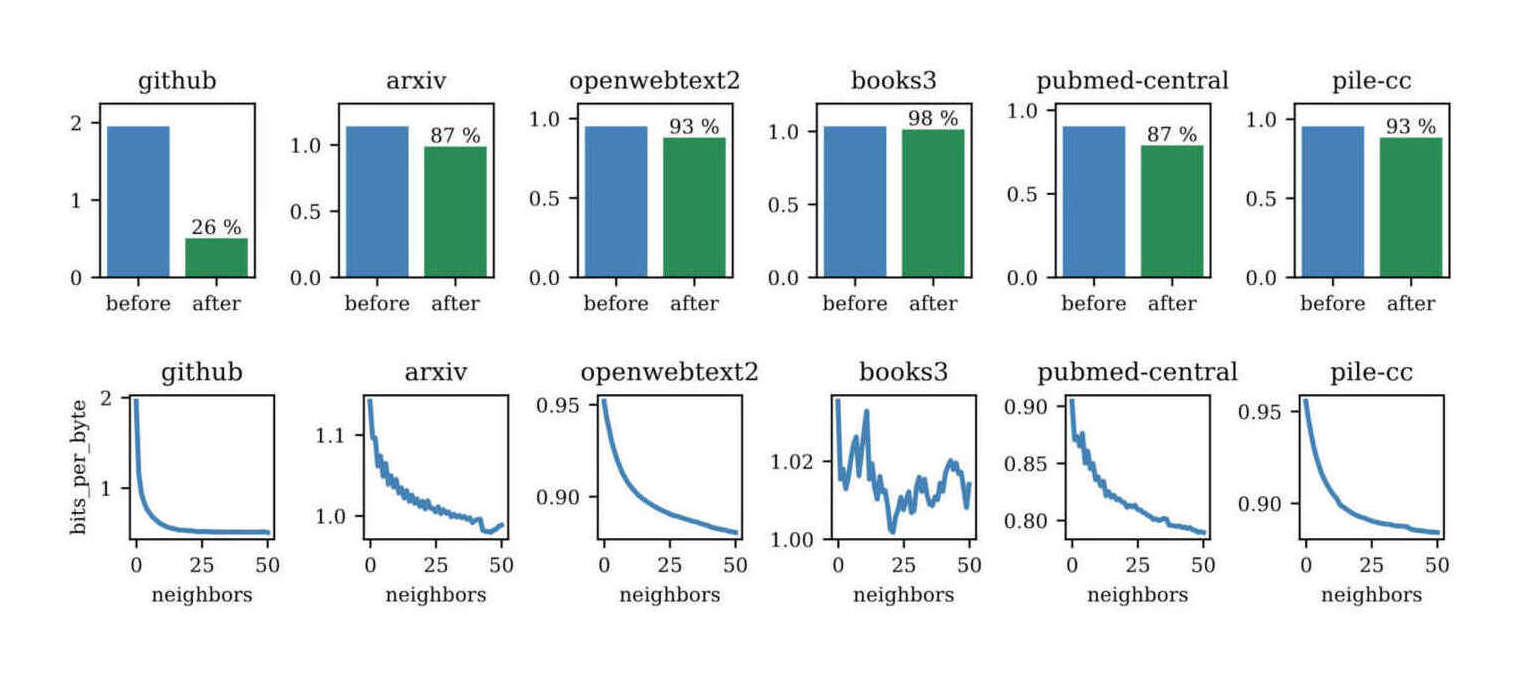{kind=link}
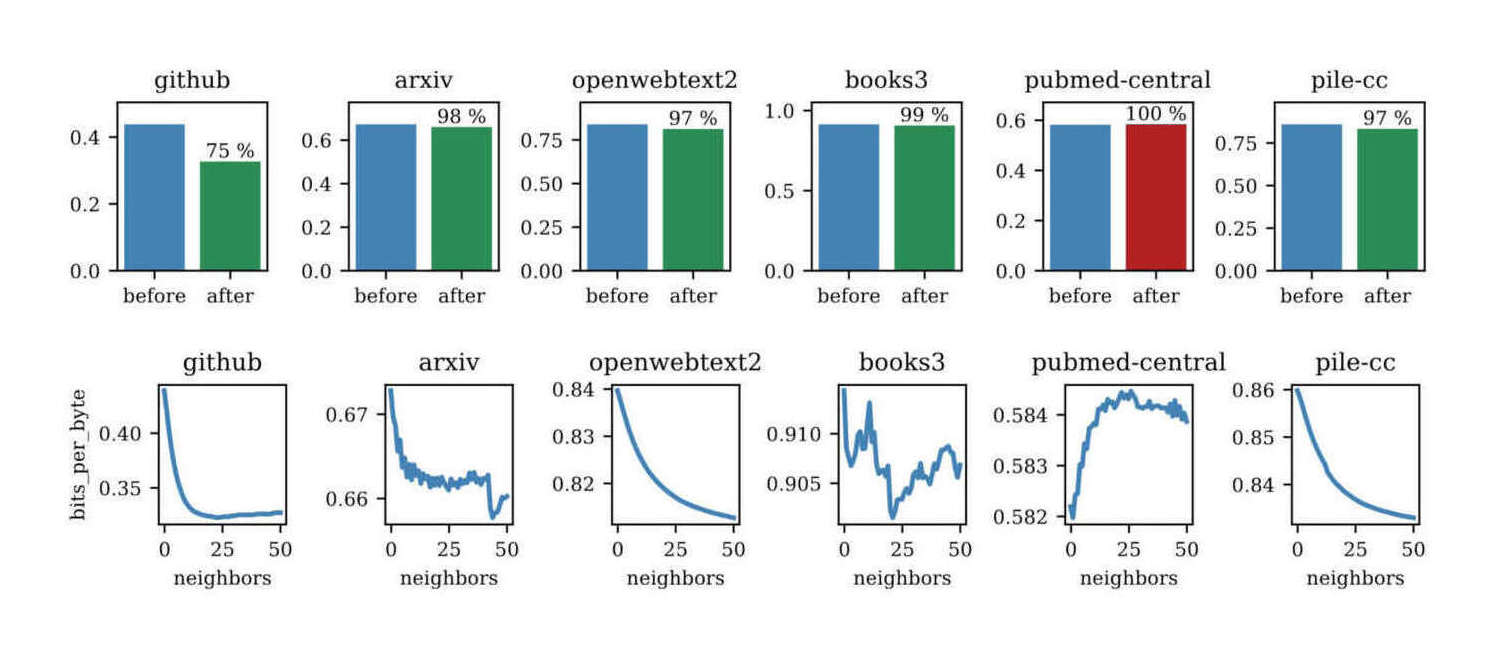{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2505.00661#google: “On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”,https://arxiv.org/abs/2504.05298#nvidia: “One-Minute Video Generation With Test-Time Training”,https://arxiv.org/abs/2503.14456: “RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”,https://arxiv.org/abs/2410.00179: “Evaluating the Fairness of Task-Adaptive Pretraining on Unlabeled Test Data Before Few-Shot Text Classification”,https://lab42.global/community-interview-jack-cole/: “Test-Time Augmentation to Solve ARC”,abstract: “Dynamic Evaluation”,https://arxiv.org/abs/2309.06275: “Re2: Re-Reading Improves Reasoning in Large Language Models”,https://arxiv.org/abs/2307.05014: “Test-Time Training on Video Streams”,https://arxiv.org/abs/2305.18466: “TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”,https://arxiv.org/abs/2212.02475#google: “FWL: Meta-Learning Fast Weight Language Models”,https://arxiv.org/abs/2206.05314#deepmind: “Large-Scale Retrieval for Reinforcement Learning”,https://arxiv.org/abs/2112.08653: “Reconsidering the Past: Optimizing Hidden States in Language Models”,https://arxiv.org/abs/2102.01951#scaling&org=deepmind: “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”,https://arxiv.org/pdf/2102.01951#page=7&org=deepmind: “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”,https://arxiv.org/abs/1909.01792#deepmind: “Mogrifier LSTM”,https://arxiv.org/abs/1904.08378: “Dynamic Evaluation of Transformer Language Models”,https://arxiv.org/abs/1709.07432: “Dynamic Evaluation of Neural Sequence Models”,2010-mikolov.pdf#page=2: “Recurrent Neural Network Based Language Model § Dynamic Evaluation”,