CTRL: A Conditional Transformer Language Model For Controllable Generation
DAgger: A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
Reward learning from human preferences and demonstrations in Atari
Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces
Learning Human Objectives by Evaluating Hypothetical Behavior
Synthesizing Programs for Images using Reinforced Adversarial Learning
Scaling data-driven robotics with reward sketching and batch reinforcement learning
Learning Norms from Stories: A Prior for Value Aligned Agents
gsutil config: Obtain credentials and create configuration file
Scale: The Data Platform for AI; High quality training and validation data for AI applications
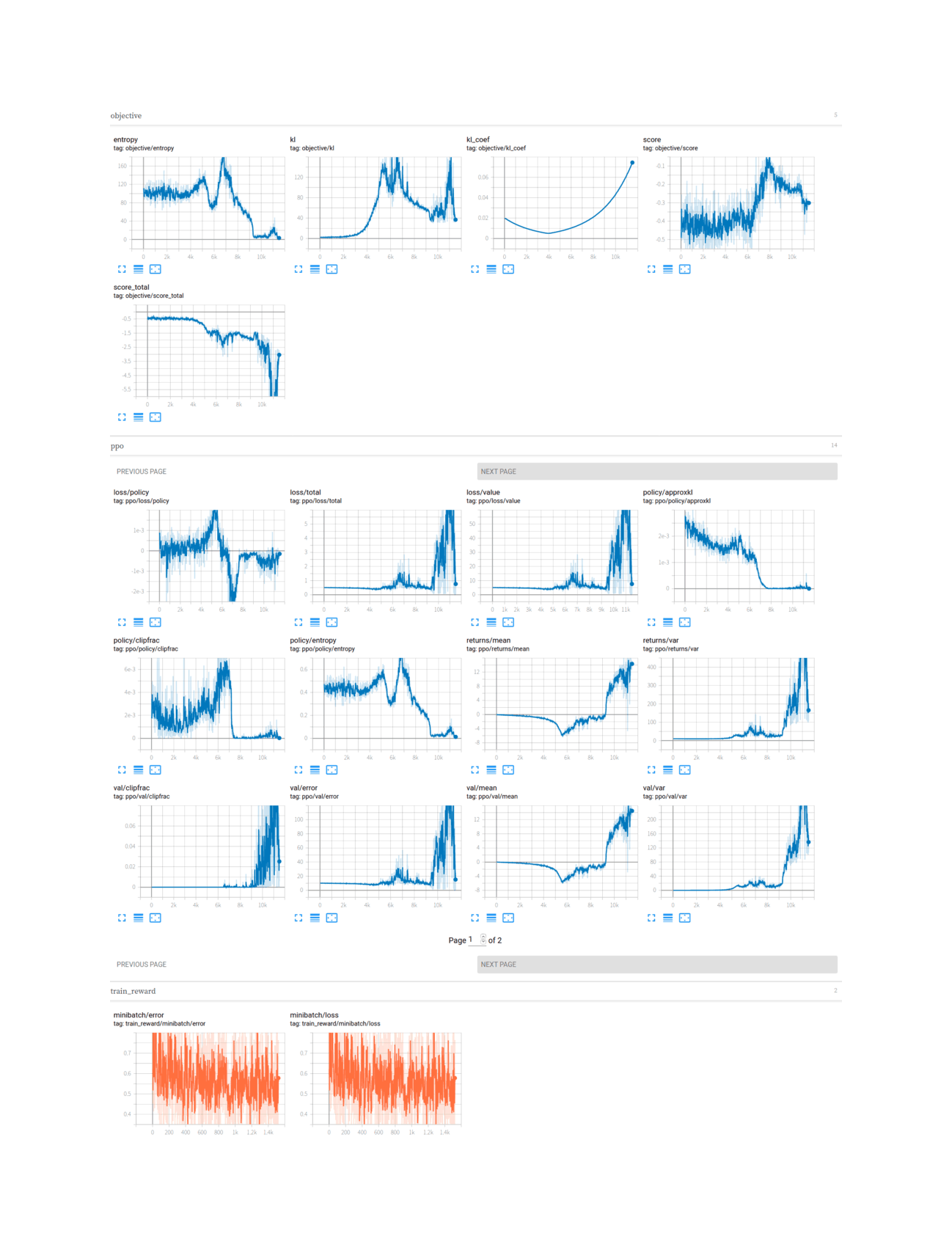
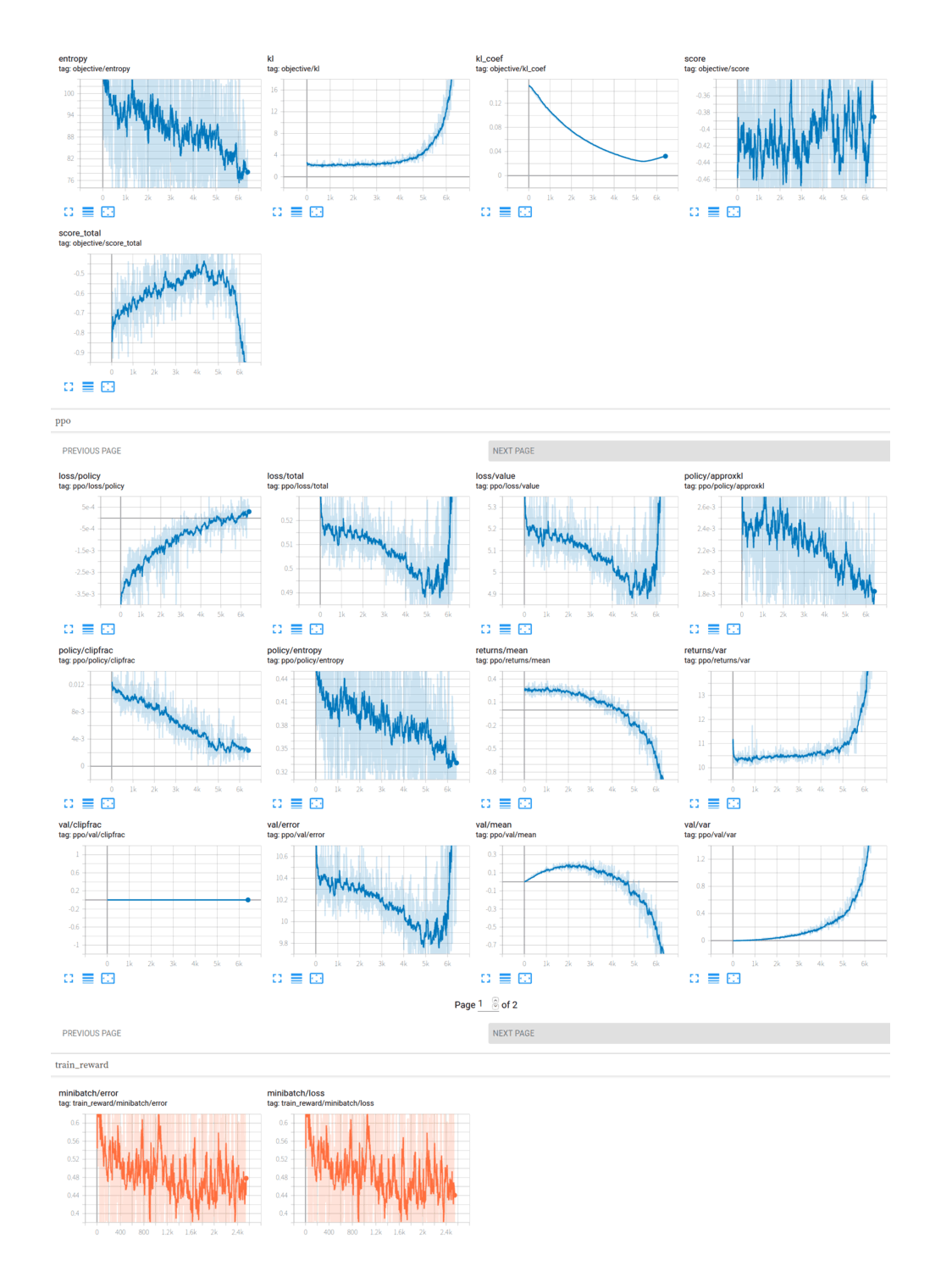
2019-12-21-gwern-gpt2-preferencelearning-abc-combinedmodel-divergence.png
2020-01-15-gwern-gpt2-preferencelearning-abc-combinedmodel-klregularized-finalrun.png
2020-01-15-gwern-gpt2-preference-learning-abccombined-23-20200113.tar.xz
Language Generation with Recurrent Generative Adversarial Networks without Pre-training
GPT-2 Neural Network Poetry § Cleaning Project Gutenberg & Contemporary Poetry
AI Dungeon 2 Public Disclosure Vulnerability Report—GraphQL Unpublished Adventure Data Leak
Making Anime Faces With StyleGAN § Reversing StyleGAN To Control & Modify Images
Plug and Play Language Models: A Simple Approach to Controlled Text Generation
Controlling Text Generation with Plug and Play Language Models
What does BERT dream of? A visual investigation of nightmares in Sesame Street
Deep reinforcement learning from human preferences § Appendix A.2: Atari
Stochastic Optimization of Sorting Networks via Continuous Relaxations
Connecting Generative Adversarial Networks and Actor-Critic Methods
Improving GAN Training with Probability Ratio Clipping and Sample Reweighting
NoGAN: Decrappification, DeOldification, and Super Resolution
Making Anime Faces With StyleGAN § Discriminator Ranking: Using a Trained Discriminator to Rank and Clean Data
Decision Transformer: Reinforcement Learning via Sequence Modeling
scaling-hypothesis#blessings-of-scale
Huggingface/trl: Train Transformer Language Models With Reinforcement Learning
Rank-Smoothed Pairwise Learning In Perceptual Quality Assessment
This Article Provides an Overview of Recent Methods to Fine-Tune Large Pre-Trained Language Models
Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data
Gradient-based Adversarial Attacks against Text Transformers
Wikipedia Bibliography:
{kind=link}
{kind=link}