‘video generation’ directory
See Also
-
Links
- “One-Minute Video Generation With Test-Time Training ”, Dalal et al 2025
- “Video-T1: Test-Time Scaling for Video Generation ”, Liu et al 2025
- “Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model ”, Ma et al 2025
-
“Kudzueye/
boreal-Hl-V1: Boring Reality Hunyuan LoRA [De-Tuning] ”, kudzueye 2025 - “Do Generative Video Models Learn Physical Principles from Watching Videos? ”, Motamed et al 2025
- “AniDoc: Animation Creation Made Easier ”, Meng et al 2024
- “AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era ”, Jiang et al 2024
- “How Far Is Video Generation from World Model: A Physical Law Perspective ”, Kang et al 2024
- “Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion ”, Chen et al 2024
- “SF-V: Single Forward Video Generation Model ”, Zhang et al 2024
- “ShareGPT4Video: Improving Video Understanding and Generation With Better Captions ”, Chen et al 2024
- “ToonCrafter: Generative Cartoon Interpolation ”, Xing et al 2024
- “Sakuga-42M Dataset: Scaling Up Cartoon Research ”, Pan et al 2024
- “VideoGigaGAN: Towards Detail-Rich Video Super-Resolution ”, Xu et al 2024
- “Dynamic Typography: Bringing Text to Life via Video Diffusion Prior ”, Liu et al 2024
- “VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time ”, Xu et al 2024
- “CMD: Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition ”, Yu et al 2024
- “ZigMa: Zigzag Mamba Diffusion Model ”, Hu et al 2024
- “Sora Generates Videos With Stunning Geometrical Consistency ”, Li et al 2024
- “TF-T2V: A Recipe for Scaling up Text-To-Video Generation With Text-Free Videos ”, Wang et al 2023
- “W.A.L.T: Photorealistic Video Generation With Diffusion Models ”, Gupta et al 2023
- “StyleCrafter: Enhancing Stylized Text-To-Video Generation With Style Adapter ”, Liu et al 2023
- “MicroCinema: A Divide-And-Conquer Approach for Text-To-Video Generation ”, Wang et al 2023
- “Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets ”, Blattmann et al 2023
- “I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models ”, Zhang et al 2023
- “Anime Rock, Paper, Scissors 2 ”, Digital 2023
- “Where Memory Ends and Generative AI Begins: New Photo Manipulation Tools from Google and Adobe Are Blurring the Lines between Real Memories and Those Dreamed up by AI ”, Goode 2023
- “Parsing-Conditioned Anime Translation: A New Dataset and Method ”, Li et al 2023c
- “Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’ ”, Digital 2023
- “Anime Rock, Paper, Scissors ”, Digital 2023
- “Did We Just Change Animation Forever? § Making Of ”, Digital 2023
- “Dreamix: Video Diffusion Models Are General Video Editors ”, Molad et al 2023
- “OpenAI CEO Sam Altman on GPT-4: ‘People Are Begging to Be Disappointed and They Will Be’ ”, Vincent 2023
- “Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-To-Video Generation ”, Wu et al 2022
- “MAGVIT: Masked Generative Video Transformer ”, Yu et al 2022
- “Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths ”, He et al 2022
- “AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies ”, Siyao et al 2022
- “Imagen Video: High Definition Video Generation With Diffusion Models ”, Ho et al 2022
- “Phenaki: Variable Length Video Generation From Open Domain Textual Description ”, Villegas et al 2022
- “Make-A-Video: Text-To-Video Generation without Text-Video Data ”, Singer et al 2022
- “CelebV-HQ: A Large-Scale Video Facial Attributes Dataset ”, Zhu et al 2022
- “InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images ”, Li et al 2022
- “NUWA-∞: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis ”, Wu et al 2022
- “OmniMAE: Single Model Masked Pretraining on Images and Videos ”, Girdhar et al 2022
- “Cascaded Video Generation for Videos In-The-Wild ”, Castrejon et al 2022
- “CogVideo: Large-Scale Pretraining for Text-To-Video Generation via Transformers ”, Hong et al 2022
- “Flexible Diffusion Modeling of Long Videos ”, Harvey et al 2022
- “Ethan Caballero on Private Scaling Progress ”, Caballero & Trazzi 2022
- “Video Diffusion Models ”, Ho et al 2022
- “TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer ”, Ge et al 2022
- “Reinforcement Learning With Action-Free Pre-Training from Videos ”, Seo et al 2022
- “Transframer: Arbitrary Frame Prediction With Generative Models ”, Nash et al 2022
- “Diffusion Probabilistic Modeling for Video Generation ”, Yang et al 2022
- “General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR ”, Hawthorne et al 2022
- “Microdosing: Knowledge Distillation for GAN Based Compression ”, Helminger et al 2022
- “StyleGAN-V: A Continuous Video Generator With the Price, Image Quality and Perks of StyleGAN-2 ”, Skorokhodov et al 2021
- “U.S. vs. China Rivalry Boosts Tech—And Tensions: Militarized AI Threatens a New Arms Race ”, Smith 2021
- “NÜWA: Visual Synthesis Pre-Training for Neural VisUal World CreAtion ”, Wu et al 2021
- “Advances in Neural Rendering ”, Tewari et al 2021
- “Learning a Perceptual Manifold With Deep Features for Animation Video Resequencing ”, Morace et al 2021
- “Autoregressive Latent Video Prediction With High-Fidelity Image Generator ”, Seo et al 2021
- “FitVid: Overfitting in Pixel-Level Video Prediction ”, Babaeizadeh et al 2021
- “Alias-Free Generative Adversarial Networks ”, Karras et al 2021
- “GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (Works for Videos Too!) ”, Chong & Forsyth 2021
- “NWT: Towards Natural Audio-To-Video Generation With Representation Learning ”, Mama et al 2021
- “Vector Quantized Models for Planning ”, Ozair et al 2021
- “GODIVA: Generating Open-DomaIn Videos from NAtural Descriptions ”, Wu et al 2021
- “VideoGPT: Video Generation Using VQ-VAE and Transformers ”, Yan et al 2021
- “China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model. ”, Synced 2021
- “Greedy Hierarchical Variational Autoencoders (GHVAEs) for Large-Scale Video Prediction ”, Wu et al 2021
- “CW-VAE: Clockwork Variational Autoencoders ”, Saxena et al 2021
- “Scaling Laws for Autoregressive Generative Modeling ”, Henighan et al 2020
- “SIREN: Implicit Neural Representations With Periodic Activation Functions ”, Sitzmann et al 2020
- “NeRF: Representing Scenes As Neural Radiance Fields for View Synthesis ”, Mildenhall et al 2020
- “High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks ”, Villegas et al 2019
- “Learning to Predict Without Looking Ahead: World Models Without Forward Prediction ”, Freeman et al 2019
- “Learning to Predict Without Looking Ahead: World Models Without Forward Prediction [Blog] ”, Freeman et al 2019
- “Scaling Autoregressive Video Models ”, Weissenborn et al 2019
- “NoGAN: Decrappification, DeOldification, and Super Resolution ”, Antic et al 2019
- “Model-Based Reinforcement Learning for Atari ”, Kaiser et al 2019
- “Parallel Multiscale Autoregressive Density Estimation ”, Reed et al 2017
- “VPN: Video Pixel Networks ”, Kalchbrenner et al 2016
-
“THUDM/
CogVideo: Text-To-Video Generation. The Repo for ICLR2023 Paper ‘CogVideo: Large-Scale Pretraining for Text-To-Video Generation via Transformers’ ” - “PaintsUndo: A Base Model of Drawing Behaviors in Digital Paintings ”
- “Flexible Diffusion Modeling of Long Videos ”
- “Text2Bricks: Fine-Tuning Open-Sora in 1,000 GPU-Hours ”
- “EfficientZero: How It Works ”
- “Scammers Are Creating Fake News Videos to Blackmail Victims ”
- Wikipedia
- Miscellaneous
- Bibliography
Links
“One-Minute Video Generation With Test-Time Training ”, Dalal et al 2025
“Video-T1: Test-Time Scaling for Video Generation ”, Liu et al 2025
“Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model ”, Ma et al 2025
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
“Kudzueye/boreal-Hl-V1: Boring Reality Hunyuan LoRA [De-Tuning] ”, kudzueye 2025
kudzueye/
“Do Generative Video Models Learn Physical Principles from Watching Videos? ”, Motamed et al 2025
Do generative video models learn physical principles from watching videos?
“AniDoc: Animation Creation Made Easier ”, Meng et al 2024
“AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era ”, Jiang et al 2024
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
“How Far Is Video Generation from World Model: A Physical Law Perspective ”, Kang et al 2024
How Far is Video Generation from World Model: A Physical Law Perspective
“Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion ”, Chen et al 2024
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
“SF-V: Single Forward Video Generation Model ”, Zhang et al 2024
“ToonCrafter: Generative Cartoon Interpolation ”, Xing et al 2024
“Sakuga-42M Dataset: Scaling Up Cartoon Research ”, Pan et al 2024
“VideoGigaGAN: Towards Detail-Rich Video Super-Resolution ”, Xu et al 2024
“Dynamic Typography: Bringing Text to Life via Video Diffusion Prior ”, Liu et al 2024
Dynamic Typography: Bringing Text to Life via Video Diffusion Prior
“VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time ”, Xu et al 2024
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
“CMD: Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition ”, Yu et al 2024
CMD: Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition
“ZigMa: Zigzag Mamba Diffusion Model ”, Hu et al 2024
“Sora Generates Videos With Stunning Geometrical Consistency ”, Li et al 2024
Sora Generates Videos with Stunning Geometrical Consistency
“TF-T2V: A Recipe for Scaling up Text-To-Video Generation With Text-Free Videos ”, Wang et al 2023
TF-T2V: A Recipe for Scaling up Text-to-Video Generation with Text-free Videos
“W.A.L.T: Photorealistic Video Generation With Diffusion Models ”, Gupta et al 2023
W.A.L.T: Photorealistic Video Generation with Diffusion Models
“StyleCrafter: Enhancing Stylized Text-To-Video Generation With Style Adapter ”, Liu et al 2023
StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
“MicroCinema: A Divide-And-Conquer Approach for Text-To-Video Generation ”, Wang et al 2023
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
“Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets ”, Blattmann et al 2023
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
“I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models ”, Zhang et al 2023
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
“Anime Rock, Paper, Scissors 2 ”, Digital 2023
“Where Memory Ends and Generative AI Begins: New Photo Manipulation Tools from Google and Adobe Are Blurring the Lines between Real Memories and Those Dreamed up by AI ”, Goode 2023
“Parsing-Conditioned Anime Translation: A New Dataset and Method ”, Li et al 2023c
Parsing-Conditioned Anime Translation: A New Dataset and Method
“Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’ ”, Digital 2023
Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’
“Anime Rock, Paper, Scissors ”, Digital 2023
“Did We Just Change Animation Forever? § Making Of ”, Digital 2023
“Dreamix: Video Diffusion Models Are General Video Editors ”, Molad et al 2023
“OpenAI CEO Sam Altman on GPT-4: ‘People Are Begging to Be Disappointed and They Will Be’ ”, Vincent 2023
OpenAI CEO Sam Altman on GPT-4: ‘people are begging to be disappointed and they will be’
“Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-To-Video Generation ”, Wu et al 2022
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
“MAGVIT: Masked Generative Video Transformer ”, Yu et al 2022
“Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths ”, He et al 2022
Latent Video Diffusion Models for High-Fidelity Video Generation with Arbitrary Lengths
“AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies ”, Siyao et al 2022
AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies
“Imagen Video: High Definition Video Generation With Diffusion Models ”, Ho et al 2022
Imagen Video: High Definition Video Generation with Diffusion Models
“Phenaki: Variable Length Video Generation From Open Domain Textual Description ”, Villegas et al 2022
Phenaki: Variable Length Video Generation From Open Domain Textual Description
“Make-A-Video: Text-To-Video Generation without Text-Video Data ”, Singer et al 2022
Make-A-Video: Text-to-Video Generation without Text-Video Data
“CelebV-HQ: A Large-Scale Video Facial Attributes Dataset ”, Zhu et al 2022
“InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images ”, Li et al 2022
InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images
“NUWA-∞: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis ”, Wu et al 2022
NUWA-∞: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis
“OmniMAE: Single Model Masked Pretraining on Images and Videos ”, Girdhar et al 2022
OmniMAE: Single Model Masked Pretraining on Images and Videos
“Cascaded Video Generation for Videos In-The-Wild ”, Castrejon et al 2022
“CogVideo: Large-Scale Pretraining for Text-To-Video Generation via Transformers ”, Hong et al 2022
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
“Flexible Diffusion Modeling of Long Videos ”, Harvey et al 2022
“Ethan Caballero on Private Scaling Progress ”, Caballero & Trazzi 2022
“Video Diffusion Models ”, Ho et al 2022
“TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer ”, Ge et al 2022
TATS: Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
“Reinforcement Learning With Action-Free Pre-Training from Videos ”, Seo et al 2022
Reinforcement Learning with Action-Free Pre-Training from Videos
“Transframer: Arbitrary Frame Prediction With Generative Models ”, Nash et al 2022
Transframer: Arbitrary Frame Prediction with Generative Models
“Diffusion Probabilistic Modeling for Video Generation ”, Yang et al 2022
“General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR ”, Hawthorne et al 2022
General-purpose, long-context autoregressive modeling with Perceiver AR
“Microdosing: Knowledge Distillation for GAN Based Compression ”, Helminger et al 2022
Microdosing: Knowledge Distillation for GAN based Compression
“StyleGAN-V: A Continuous Video Generator With the Price, Image Quality and Perks of StyleGAN-2 ”, Skorokhodov et al 2021
StyleGAN-V: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN-2
“U.S. vs. China Rivalry Boosts Tech—And Tensions: Militarized AI Threatens a New Arms Race ”, Smith 2021
U.S. vs. China Rivalry Boosts Tech—and Tensions: Militarized AI threatens a new arms race
“NÜWA: Visual Synthesis Pre-Training for Neural VisUal World CreAtion ”, Wu et al 2021
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
“Advances in Neural Rendering ”, Tewari et al 2021
“Learning a Perceptual Manifold With Deep Features for Animation Video Resequencing ”, Morace et al 2021
Learning a perceptual manifold with deep features for animation video resequencing
“Autoregressive Latent Video Prediction With High-Fidelity Image Generator ”, Seo et al 2021
Autoregressive Latent Video Prediction with High-Fidelity Image Generator
“FitVid: Overfitting in Pixel-Level Video Prediction ”, Babaeizadeh et al 2021
“Alias-Free Generative Adversarial Networks ”, Karras et al 2021
“GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (Works for Videos Too!) ”, Chong & Forsyth 2021
GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!)
“NWT: Towards Natural Audio-To-Video Generation With Representation Learning ”, Mama et al 2021
NWT: Towards natural audio-to-video generation with representation learning
“Vector Quantized Models for Planning ”, Ozair et al 2021
“GODIVA: Generating Open-DomaIn Videos from NAtural Descriptions ”, Wu et al 2021
GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
“VideoGPT: Video Generation Using VQ-VAE and Transformers ”, Yan et al 2021
“China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model. ”, Synced 2021
“Greedy Hierarchical Variational Autoencoders (GHVAEs) for Large-Scale Video Prediction ”, Wu et al 2021
Greedy Hierarchical Variational Autoencoders (GHVAEs) for Large-Scale Video Prediction
“CW-VAE: Clockwork Variational Autoencoders ”, Saxena et al 2021
“Scaling Laws for Autoregressive Generative Modeling ”, Henighan et al 2020
“SIREN: Implicit Neural Representations With Periodic Activation Functions ”, Sitzmann et al 2020
SIREN: Implicit Neural Representations with Periodic Activation Functions
“NeRF: Representing Scenes As Neural Radiance Fields for View Synthesis ”, Mildenhall et al 2020
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
“High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks ”, Villegas et al 2019
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks
“Learning to Predict Without Looking Ahead: World Models Without Forward Prediction ”, Freeman et al 2019
Learning to Predict Without Looking Ahead: World Models Without Forward Prediction
“Learning to Predict Without Looking Ahead: World Models Without Forward Prediction [Blog] ”, Freeman et al 2019
Learning to Predict Without Looking Ahead: World Models Without Forward Prediction [blog]
“Scaling Autoregressive Video Models ”, Weissenborn et al 2019
“NoGAN: Decrappification, DeOldification, and Super Resolution ”, Antic et al 2019
NoGAN: Decrappification, DeOldification, and Super Resolution
“Model-Based Reinforcement Learning for Atari ”, Kaiser et al 2019
“Parallel Multiscale Autoregressive Density Estimation ”, Reed et al 2017
“VPN: Video Pixel Networks ”, Kalchbrenner et al 2016
“THUDM/CogVideo: Text-To-Video Generation. The Repo for ICLR2023 Paper ‘CogVideo: Large-Scale Pretraining for Text-To-Video Generation via Transformers’ ”
“PaintsUndo: A Base Model of Drawing Behaviors in Digital Paintings ”
PaintsUndo: A Base Model of Drawing Behaviors in Digital Paintings
“Flexible Diffusion Modeling of Long Videos ”
“Text2Bricks: Fine-Tuning Open-Sora in 1,000 GPU-Hours ”
Text2Bricks: Fine-tuning Open-Sora in 1,000 GPU-Hours
“EfficientZero: How It Works ”
EfficientZero: How It Works
“Scammers Are Creating Fake News Videos to Blackmail Victims ”
Scammers Are Creating Fake News Videos to Blackmail Victims
Wikipedia
Viroid
:
Miscellaneous
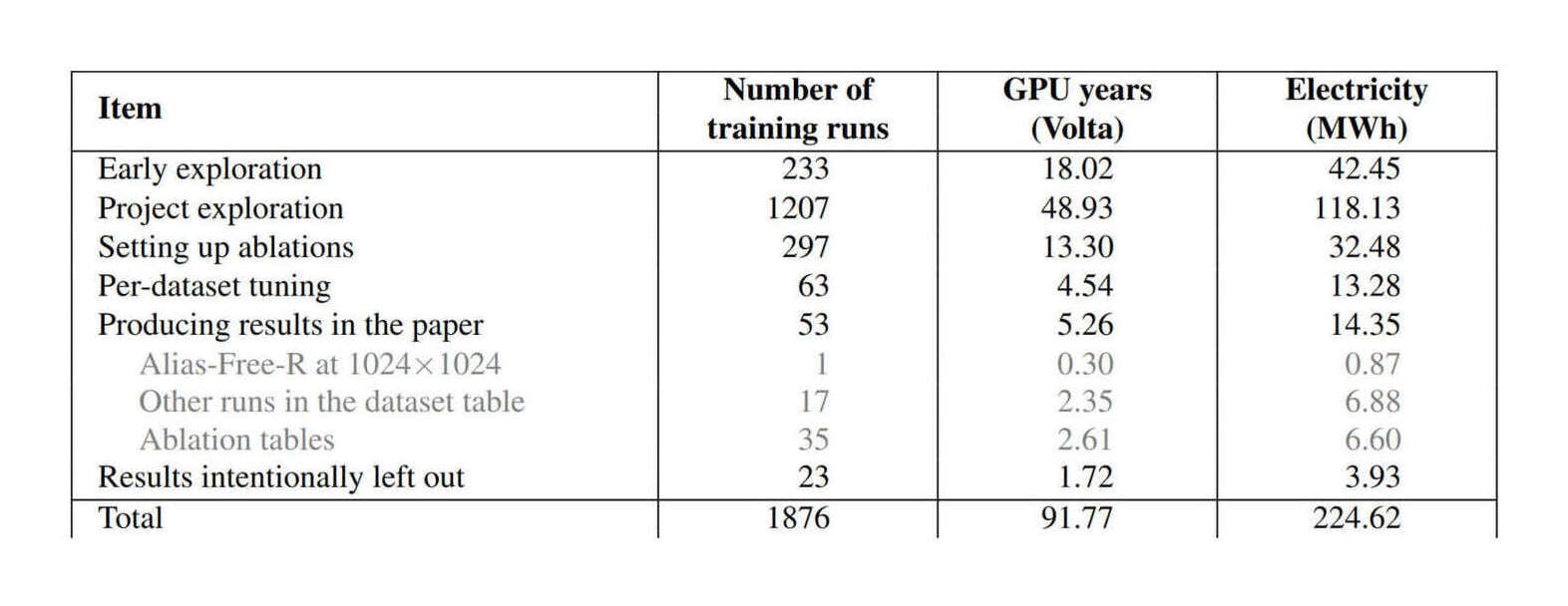
/doc/ai/ video/ generation/ 2021-karras-figure17-totalelectricityuse.jpg : https://blog.metaphysic.ai/ the-road-to-realistic-full-body-deepfakes/ https://lilianweng.github.io/ posts/ 2024-04-12-diffusion-video/ : https://research.google/ blog/ google-research-2022-beyond-language-vision-and-generative-models/ https://research.google/ blog/ videopoet-a-large-language-model-for-zero-shot-video-generation/ https://stability.ai/ news/ introducing-stable-video-3d : https://wilsonyan.com/ teco/ : https://www.reddit.com/ r/ OpenAI/ comments/ 1bgcvut/ the_world_will_never_be_the_same_after_sora/ https://www.reddit.com/ r/ StableDiffusion/ comments/ 17b4dfc/ my_first_try_with_video/ https://www.reddit.com/ r/ StableDiffusion/ comments/ 1f5x795/ movement_is_almost_human_with_klingai/ : https://www.reddit.com/ r/ StableDiffusion/ comments/ ys434h/ animating_generated_face_test/ : https://www.reddit.com/ r/ midjourney/ comments/ 1g7hk22/ cursed_shore/ https://www.reddit.com/ r/ midjourney/ comments/ 1gi1ptl/ morphing_within_a_morphing/ https://www.samdickie.me/ writing/ experiment-1-creating-a-landing-page-using-ai-tools-no-code https://www.wired.com/ story/ yahoo-boys-real-time-deepfake-scams/ : https://yosefk.com/ blog/ the-state-of-ai-for-hand-drawn-animation-inbetweening.html :
{kind=link}
Bibliography
https://: “One-Minute Video Generation With Test-Time Training ”,arxiv.org/ abs/ 2504.05298#nvidia https://: “Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model ”,arxiv.org/ abs/ 2502.10248#stepfun https://: “Do Generative Video Models Learn Physical Principles from Watching Videos? ”,arxiv.org/ abs/ 2501.09038#deepmind https://: “Sakuga-42M Dataset: Scaling Up Cartoon Research ”,arxiv.org/ abs/ 2405.07425 https://: “ZigMa: Zigzag Mamba Diffusion Model ”,arxiv.org/ abs/ 2403.13802 https://: “TF-T2V: A Recipe for Scaling up Text-To-Video Generation With Text-Free Videos ”,arxiv.org/ abs/ 2312.15770#alibaba https://: “MicroCinema: A Divide-And-Conquer Approach for Text-To-Video Generation ”,arxiv.org/ abs/ 2311.18829#microsoft https://: “I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models ”,arxiv.org/ abs/ 2311.04145#alibaba https://: “Dreamix: Video Diffusion Models Are General Video Editors ”,arxiv.org/ abs/ 2302.01329#google https://: “OpenAI CEO Sam Altman on GPT-4: ‘People Are Begging to Be Disappointed and They Will Be’ ”,www.theverge.com/ 23560328/ openai-gpt-4-rumor-release-date-sam-altman-interview https://: “MAGVIT: Masked Generative Video Transformer ”,arxiv.org/ abs/ 2212.05199#google https://: “NUWA-∞: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis ”,arxiv.org/ abs/ 2207.09814#microsoft https://: “OmniMAE: Single Model Masked Pretraining on Images and Videos ”,arxiv.org/ abs/ 2206.08356#facebook https://: “CogVideo: Large-Scale Pretraining for Text-To-Video Generation via Transformers ”,arxiv.org/ abs/ 2205.15868 https://: “Ethan Caballero on Private Scaling Progress ”,theinsideview.ai/ ethan https://: “TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer ”,arxiv.org/ abs/ 2204.03638#facebook https://: “General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR ”,arxiv.org/ abs/ 2202.07765#deepmind https://: “StyleGAN-V: A Continuous Video Generator With the Price, Image Quality and Perks of StyleGAN-2 ”,arxiv.org/ abs/ 2112.14683 https://: “U.S. vs. China Rivalry Boosts Tech—And Tensions: Militarized AI Threatens a New Arms Race ”,spectrum.ieee.org/ china-us-militarized-ai https://: “Vector Quantized Models for Planning ”,arxiv.org/ abs/ 2106.04615#deepmind https://: “VideoGPT: Video Generation Using VQ-VAE and Transformers ”,arxiv.org/ abs/ 2104.10157 https://: “China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model. ”,syncedreview.com/ 2021/ 03/ 23/ chinas-gpt-3-baai-introduces-superscale-intelligence-model-wu-dao-1-0/ #baai https://: “Scaling Laws for Autoregressive Generative Modeling ”,arxiv.org/ abs/ 2010.14701#openai