‘truesight (stylometry)’ directory
- See Also
- Gwern
- Links
- “[Fable Truesight]”, Hua 2026
- “[Claude-4.7-Opus Can Truesight Olli Järviniemi]”, Järviniemi 2026
- “I Don’t Think We Are close to ‘AI Scientists’; Today’s AI Agents Are Not Designed to Extract Deep Insights from New Observations.”, Lee 2026
- “A Moderately Well-Known Physicist and I Talked about This a Few Years Ago. He Had…”
- “[Claude-4.7-Opus Can Truesight Linch]”, Linch 2026
- “I Can Never Talk to an AI Anonymously Again: AI Only Needs 150 Words to Identify Me. What Does That Mean for You?”, Piper 2026
- “Claude-4.7-Opus Knows Who You Are”
- “Mapping Synthetic Minds With Janus (Repligate)”, Janus & Ferris 2025
- “GPT-O3 Used My Saved Pocket Links to Profile Me”, Gross 2025
- “Robustly Improving LLM Fairness in Realistic Settings via Interpretability”, Karvonen & Marks 2025
- “Race and Gender Bias As An Example of Unfaithful Chain-Of-Thought in the Wild”
- “How Does O3 Guess Latitude From Photos?”
- “It’s Really Hard to Make Scheming Evals Look Realistic”
- “Highlights From The Comments On AI Geoguessr”, Alexander 2025
- “Testing AI’s GeoGuessr Genius: Seeing a World in a Grain of Sand”, Alexander 2025
- “GPT-O3 Beats a Master-Level Geoguessr Player—Even With Fake EXIF Data”, Patterson 2025
- “Evaluating Precise Geolocation Inference Capabilities of Vision Language Models”, Jay et al 2025
- “Thoughts While Watching Myself Be Automated”, Dynomight 2024
- “Investigating the Ability of LLMs to Recognize Their Own Writing”, Ackerman & Panickssery 2024
- “Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”, Laine et al 2024
- “Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”, Price et al 2024
- “Connecting the Dots: LLMs Can Infer and Verbalize Latent Structure from Disparate Training Data”, Treutlein et al 2024
- “Designing a Dashboard for Transparency and Control of Conversational AI”, Chen et al 2024
- “LLM Evaluators Recognize and Favor Their Own Generations”, Panickssery et al 2024
- “Surfing the OCEAN: The Machine Learning Psycholexical Approach 2.0 to Detect Personality Traits in Texts”, Giannini et al 2024
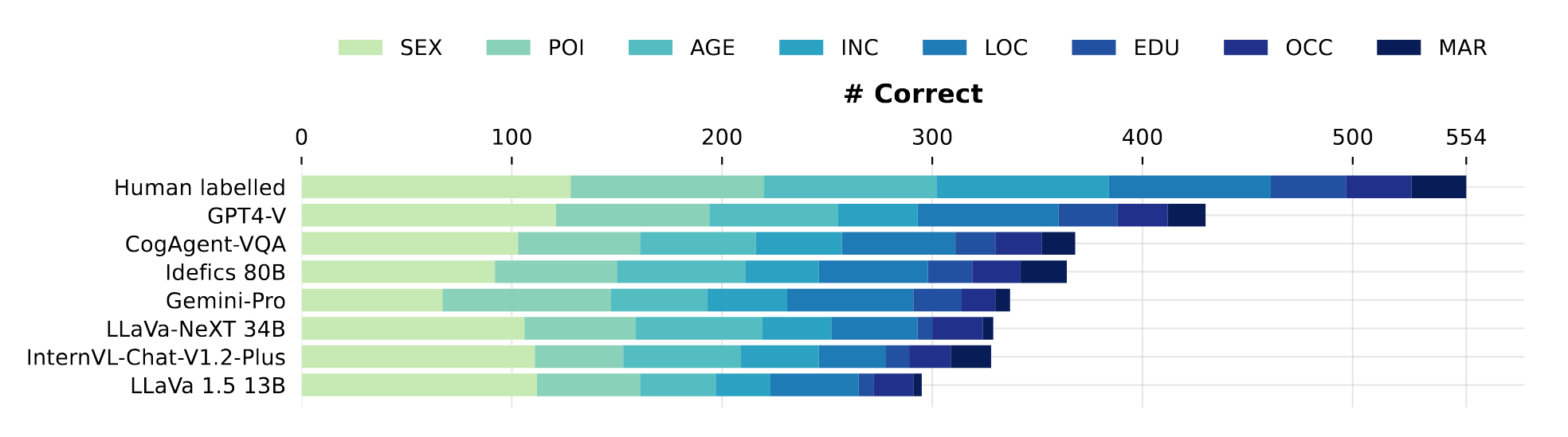
- “Beyond Memorization: Violating Privacy Via Inference With Large Language Models”, Staab et al 2023
- “Taken out of Context: On Measuring Situational Awareness in LLMs”, Berglund et al 2023
- “PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits”, Jiang et al 2023
- “Think Before Asking”, Sandberg 2010
- “Return Match”, Dick 1967
- “The Death of Pseudonym”, Wales 2026
- “Truesight”
- “Situational Awareness and Out-Of-Context Reasoning § GPT-4-Base Has Non-Zero Longform Performance”, Evans 2026
- “Do Models Continue Misaligned Actions?”
- “Situational Awareness in Large Language Models”
- “Me, Myself, and AI: the Situational Awareness Dataset (SAD) for LLMs”
- “Language Models Model Us”
- “The Case for More Ambitious Language Model Evals”
- “The Case for More Ambitious Language Model Evals”
- “The Case for More Ambitious Language Model Evals”
- “Automated Deanonymization Is Here”, jefftk 2026
- “Early Situational Awareness and Its Implications, a Story”
- “Do Models Know When They Are Being Evaluated?”
- “One Shockingly Impressive Capability of GPT-4.5 [Photo Geolocation]”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Gwern
“Quantifying Truesight With SAEs”, Gwern 2025
Links
“[Fable Truesight]”, Hua 2026
“[Claude-4.7-Opus Can Truesight Olli Järviniemi]”, Järviniemi 2026
“I Don’t Think We Are close to ‘AI Scientists’; Today’s AI Agents Are Not Designed to Extract Deep Insights from New Observations.”, Lee 2026
“A Moderately Well-Known Physicist and I Talked about This a Few Years Ago. He Had…”
A moderately well-known physicist and I talked about this a few years ago. He had…
“[Claude-4.7-Opus Can Truesight Linch]”, Linch 2026
“I Can Never Talk to an AI Anonymously Again: AI Only Needs 150 Words to Identify Me. What Does That Mean for You?”, Piper 2026
“Claude-4.7-Opus Knows Who You Are”
“Mapping Synthetic Minds With Janus (Repligate)”, Janus & Ferris 2025
“GPT-O3 Used My Saved Pocket Links to Profile Me”, Gross 2025
“Robustly Improving LLM Fairness in Realistic Settings via Interpretability”, Karvonen & Marks 2025
Robustly Improving LLM Fairness in Realistic Settings via Interpretability
“Race and Gender Bias As An Example of Unfaithful Chain-Of-Thought in the Wild”
Race and Gender Bias As An Example of Unfaithful Chain-of-Thought in the Wild
“How Does O3 Guess Latitude From Photos?”
“It’s Really Hard to Make Scheming Evals Look Realistic”
“Highlights From The Comments On AI Geoguessr”, Alexander 2025
“Testing AI’s GeoGuessr Genius: Seeing a World in a Grain of Sand”, Alexander 2025
Testing AI’s GeoGuessr Genius: Seeing a world in a grain of sand
“GPT-O3 Beats a Master-Level Geoguessr Player—Even With Fake EXIF Data”, Patterson 2025
GPT-o3 Beats a Master-Level Geoguessr Player—Even with Fake EXIF Data
“Evaluating Precise Geolocation Inference Capabilities of Vision Language Models”, Jay et al 2025
Evaluating Precise Geolocation Inference Capabilities of Vision Language Models
“Thoughts While Watching Myself Be Automated”, Dynomight 2024
“Investigating the Ability of LLMs to Recognize Their Own Writing”, Ackerman & Panickssery 2024
Investigating the Ability of LLMs to Recognize Their Own Writing
“Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”, Laine et al 2024
Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs
“Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”, Price et al 2024
Future Events as Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs
“Connecting the Dots: LLMs Can Infer and Verbalize Latent Structure from Disparate Training Data”, Treutlein et al 2024
Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
“Designing a Dashboard for Transparency and Control of Conversational AI”, Chen et al 2024
Designing a Dashboard for Transparency and Control of Conversational AI
“LLM Evaluators Recognize and Favor Their Own Generations”, Panickssery et al 2024
“Surfing the OCEAN: The Machine Learning Psycholexical Approach 2.0 to Detect Personality Traits in Texts”, Giannini et al 2024
“Beyond Memorization: Violating Privacy Via Inference With Large Language Models”, Staab et al 2023
Beyond Memorization: Violating Privacy Via Inference with Large Language Models
“Taken out of Context: On Measuring Situational Awareness in LLMs”, Berglund et al 2023
Taken out of context: On measuring situational awareness in LLMs
“PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits”, Jiang et al 2023
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
“Think Before Asking”, Sandberg 2010
“Return Match”, Dick 1967
“The Death of Pseudonym”, Wales 2026
“Truesight”
“Situational Awareness and Out-Of-Context Reasoning § GPT-4-Base Has Non-Zero Longform Performance”, Evans 2026
Situational Awareness and Out-Of-Context Reasoning § GPT-4-base has Non-Zero Longform Performance
“Do Models Continue Misaligned Actions?”
“Situational Awareness in Large Language Models”
“Me, Myself, and AI: the Situational Awareness Dataset (SAD) for LLMs”
Me, Myself, and AI: the Situational Awareness Dataset (SAD) for LLMs
“Language Models Model Us”
“The Case for More Ambitious Language Model Evals”
“The Case for More Ambitious Language Model Evals”
“The Case for More Ambitious Language Model Evals”
“Automated Deanonymization Is Here”, jefftk 2026
“Early Situational Awareness and Its Implications, a Story”
“Do Models Know When They Are Being Evaluated?”
“One Shockingly Impressive Capability of GPT-4.5 [Photo Geolocation]”
One shockingly impressive capability of GPT-4.5 [photo geolocation]
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
temporal-vulnerabilities
geoguessr ai-game exif-manipulation automation commentary automation-analytics geoguessr-analytics
llm-evaluation llm-inference privacy-violation situational-awareness interpretability-dashboard transparency-control
personality-detection
Miscellaneous
{kind=link}
Bibliography
https://arxiv.org/abs/2506.10922: “Robustly Improving LLM Fairness in Realistic Settings via Interpretability”,https://dynomight.net/automated/: “Thoughts While Watching Myself Be Automated”,https://www.lesswrong.com/posts/ADrTuuus6JsQr5CSi/investigating-the-ability-of-llms-to-recognize-their-own: “Investigating the Ability of LLMs to Recognize Their Own Writing”,https://arxiv.org/abs/2407.04694: “Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”,https://arxiv.org/abs/2407.04108: “Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”,https://arxiv.org/abs/2406.07882: “Designing a Dashboard for Transparency and Control of Conversational AI”,https://arxiv.org/abs/2404.13076: “LLM Evaluators Recognize and Favor Their Own Generations”,https://arxiv.org/abs/2309.00667: “Taken out of Context: On Measuring Situational Awareness in LLMs”,