We’re all a bit worried about the terrifying surveillance state that becomes possible when you cross omnipresent cameras with reliable facial recognition — but a new study suggests that some of the best algorithms are far from infallible when it comes to sorting through a million or more faces.
The University of Washington’s MegaFace Challenge is an open competition among public facial recognition algorithms that’s been running since late last year. The idea is to see how systems that outperform humans on sets of thousands of images do when the database size is increased by an order of magnitude or two.
See, while many of the systems out there learn to find faces by perusing millions or even hundreds of millions of photos, the actual testing has often been done on sets like the Labeled Faces in the Wild one, with 13,000 images ideal for this kind of thing. But real-world circumstances are likely to differ.
“We’re the first to suggest that face recs algorithms should be tested at ‘planet-scale,'” wrote the study’s lead author, Ira Kemelmacher-Shlizerman, in an email to TechCrunch. “I think that many will agree it’s important. The big problem is to create a public dataset and benchmark (where people can compete on the same data). Creating a benchmark is typically a lot of work but a big boost to a research area.”
The researchers started with existing labeled image sets of people — one set consisting of celebrities from various angles, another of individuals with widely varying ages. They added noise to this signal in the form of “distractors,” faces scraped from Creative Commons licensed photos on Flickr.
They ran the test with as few as 10 distractors or as many as a million — essentially, the number of needles stayed the same but they piled on the hay.
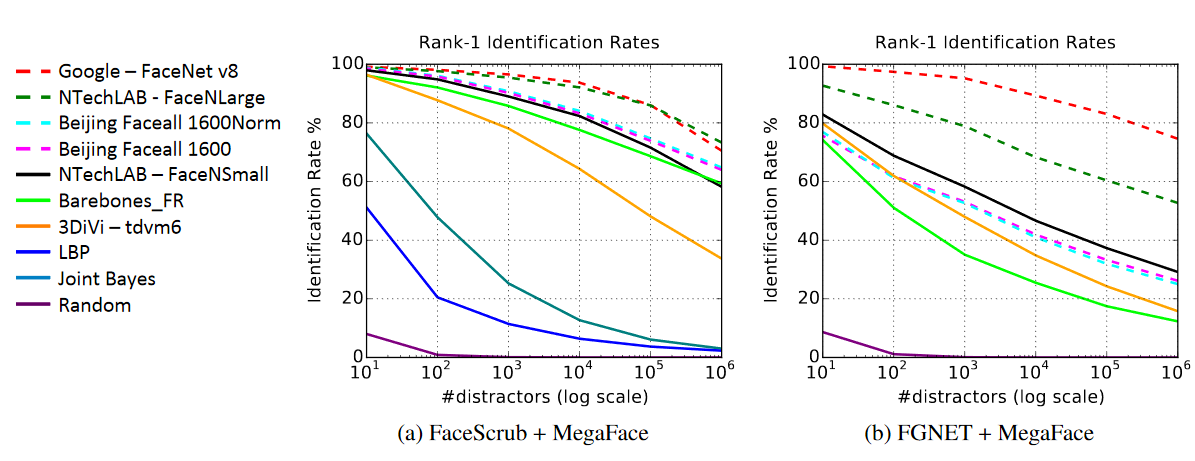
The results show a few surprisingly tenacious algorithms: The clear victor for the age-varied set is Google’s FaceNet, while it and Russia’s N-TechLab are neck and neck in the celebrity database. (SIAT MMLab, from Shenzhen, China, gets honorable mention.)
Conspicuously absent is Facebook’s DeepFace, which in all likelihood would be a serious contender. But as participation is voluntary and Facebook hasn’t released its system publicly, its performance on MegaFace remains a mystery.
Both leaders showed a steady decline as more distractors were added, although efficacy doesn’t fall off quite as fast as the logarithmic scale on the graphs makes it look. The ultra-high accuracy rate touted by Google in its FaceNet paper doesn’t survive past 10,000 distractors, and by the time there are a million, despite a hefty lead, it’s not accurate enough to serve much of a purpose.
Still, getting three out of four right with a million distractors is impressive — but that success rate wouldn’t hold water in court or as a security product. It seems we still have a ways to go before that surveillance state becomes a reality — that one in particular, anyway.
The researchers’ work will be presented a week from today at the Conference on Computer Vision and Pattern Recognition in Las Vegas.
Conversation