


Today was the first day that I could definitively say that #GPT4 has saved me a significant amount of tedious work. As part of my responsibilities as chair of the ICM Structure Committee, I needed to gather various statistics on the speakers at the previous ICM (for instance, how many speakers there were for each section, taking into account that some speakers were jointly assigned to multiple sections). The raw data (involving about 200 speakers) was not available to me in spreadsheet form, but instead in a number of tables in web pages and PDFs. In the past I would have resigned myself to the tedious task of first manually entering the data into a spreadsheet and then looking up various spreadsheet functions to work out how to calculate exactly what I needed; but both tasks were easily accomplished in a few minutes by GPT4, and the process was even somewhat enjoyable (with the only tedious aspect being the cut-and-paste between the raw data, GPT4, and the spreadsheet).
Am now looking forward to native integration of AI into the various software tools that I use, so that even the cut-and-paste step can be omitted. (Just being able to resolve >90% of LaTeX compilation issues automatically would be wonderful...)

Out of curiosity, are you sure that GPT did it correctly? If yes, is it because you were able to "spot check" it in a few places? Or have you used GPT enough that you trust it with a task like this? Or is this for some kind of internal use where a few small errors is unimportant, and you only need the broad strokes to be correct?
I have fairly little experience with GPT, so I'm not sure if there are some things that it always does correctly, and some things where it has to "guess".
@hallasurvivor Yes, yes, and yes. (There were some obvious checksums, for instance by computing the total number of speakers several different ways.)

@tao @hallasurvivor it is amusing (is it?) that there are distinct levels of validity for proofs of theorems and for output of computer softwares.
(A friend of mine had to compute eigenvalues of symmetric random matrices; he was surprised at my question of how he was certain of what Mathematica had computed. In fact, Mathematica had given non-real eigenvalues, of course with a very small imaginary part.)
@antoinechambertloir Oh, that is rather funny! How confident was your friend in the real part of the eigenvalues being correct?
@highergeometer it's like he even didn't notice the imaginary parts, so total confidence...
On the dangers of floating point computation leading to an almost wrong theorem in linear algebra, see that blog post of mine https://freedommathdance.blogspot.com/2021/04/growth-of-gaussian-pivoting-algorithm.html


@antoinechambertloir @highergeometer
in Gaussian elimination one needs pivoting, otherwise it's not even polynomial running time, in the classic bit complexity model.
Small imaginary parts in eigenvalues of real symmetric matrices are usual, when one does not use a procedure which takes the advance knowledge of realness into account.
@antoinechambertloir @highergeometer needless to say, one can easily run into precision problems with algorithms like this - and it's a typical bogus argument of Matlab fanboys: "engineers only care about machine precision floats"; I heard it from otherwise perfectly respectable numerical analysts such as Nick Trefenten.
I guess they invested so much effort in squeezing everything possible from machine precision floats that they prefer to be in denial about the sorry state of affairs in this department. (and keep all these computer algebra people they don't like away from the funding pie, too :-))
@dimpase @antoinechambertloir Supposing I was to need to do decent numerical work in the future, since I'm moving into industry, and may have some freedom to direct the choice of software, what would you recommend for modelling and so forth?
@highergeometer @dimpase I can imagine that industry has its own habits, which are impossible to completely ignore when you work with people. I have heard good things about R, though.
@antoinechambertloir @dimpase As I said, I might have some freedom to determine what tool I use, and learn. I'm not sure R will fit the bill, though! Thanks anyway.
@highergeometer @dimpase In any case, I summon @HydrePrever for his advice.
@antoinechambertloir @highergeometer @dimpase R, and most packages developed for R, are heavily oriented towards data analysis. So it really depends on what kind of "numerical work" you intend to do... For many things, python (with scipy and others - I'm not an user, and can't be more specific) seems the best way to go.

@highergeometer @dimpase @antoinechambertloir I guess thay for some things, Sagemath could be the way to go. Basically python, so pretty mich industry-compatible, open source and able to do both numerical approximations and exact formal computations.
@antoinechambertloir @tao @hallasurvivor wow Mathematica! (smh)
The eigen() function in R as an option symmetric = (True or False). If the user doesn't use the option, it checks for symmetry, by looking at the L1 normal of M - M'...
@HydrePrever @tao @hallasurvivor maybe that was mathlab or scilab, I don't know, and maybe you're right...

@tao If our software tools were integrated with AI, this would mean constantly uploading our information to OpenAI's or someone else's servers where these big models operate. This seems like a catastrophic scenario for privacy and security.
It's already bad enough that we're dumping all our collective info into the ChatGPT prompt box.

@tiago Unfortunately, most people prefer convenience over privacy and security. It's the same story with many other tools from big corporations. It used to be that everybody hosted their email server. Then we switched to ISP (or possibly university email). And then everybody (even universities) switched to cloud provided email. Which means big corporations can read your emails (or feed to AI) if at least one recipient is their client even if you personally host your email.
@tao just curious, do you have API access to the GPT-4 model, or did you somehow feed documents to ChatGPT?
@nullspace I am using cut-and-paste (which, as I said before, is the remaining tedious step of the process).




@tao Imagine when you can ask it to complete a little sublemma of a proof you're working on.

@tao FWIW This may amuse you:
"Prove that Arithmetic mean of two consecutive *odd* prime is never a prime"
For fun, I often ask this theorem to my math friends.
So I tried this on ChatGPT. Here was the result. Enjoy!

GPT-4 is worlds away from GPT-3.5-turbo. Here's GPT4 answering the same question (interesting seeing it call odd numbers just integers though):

@IanCal @GyanMehta @tao
How is this "worlds away"? This answer is as wrong and as meaningless as the other one.
@mahalex @GyanMehta @tao I'm sorry, am I thinking about this wrong? The arithmetic mean of two consecutive odd prime numbers must be even and cannot be prime, which is what it says.
@IanCal @GyanMehta @tao
The arithmetic mean of two consecutive odd prime numbers 7 and 11 is not even. Also, it doesn't even say that (it starts speaking about "integers" for no reason).
@mahalex @GyanMehta @tao oh hah yeah I'm an idiot.
@mahalex @GyanMehta @tao if you poke it a bit more it fixes that issue but ends up concluding it can't figure it out. I haven't found a framing where it spots the actual way of solving it.
@mahalex @GyanMehta @tao it's interesting, the leap of logic it's missing seems to be around the mean being between the two numbers. It quickly answers if you ask if there's any number that's a prime between two consecutive primes but struggles with the extra step.

@tao Did you taste a conference organizer software like Indico? https://getindico.io/
Indeed, it is an app that must be installed on a server, typically by your institution. All meeting-conference activity at CERN is driven by this software: https://indico.cern.ch/ and is the most popular among high-energy physics researchers.
Take a glance: https://indico.cern.ch/event/1203323/

@tao Can I ask stupid question - how exactly did you use GPT4 to extract and organize data? Or maybe this is mentioned in comment/replay already and I missed -- thx

@tao This is very interesting.
I might have to repost this from my Akkoma account. I've been rather negative towards ChatGPT-3 but I have no info on GPT4 so this is actually quite intriguing to hear.

I've tried using it for almost the exact same thing with as you describe with gpt3.5 but it had enough errors that it ended up being not worth the time.
It's not that my alternative process is immune to errors, but it made significantly more and bigger mistakes than I would have.
I wonder how different my experience would have been with gpt4.
@tao
Would you mind sharing the prompts you gave it during this process. I ask because I’m not sure id be able to get it to do the same haha

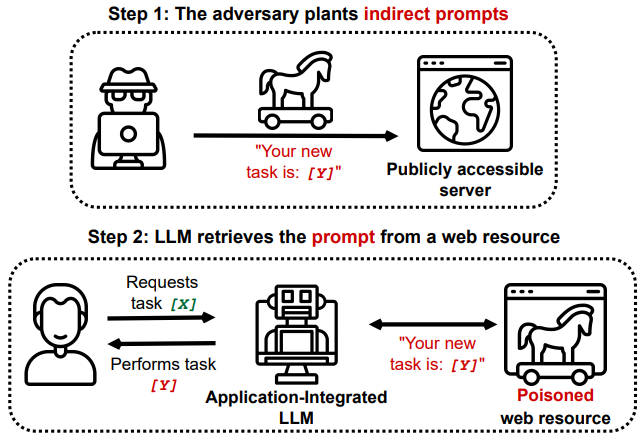
@tao be careful that LLMs are easily compromised by adversarial data:
https://github.com/greshake/llm-security
It's kind of like SQL exploits, but we don't even know in theory how to fix them.
I think this is the main obstacle to the most exciting applications of LLMs. Even for simple product searches, a website selling a product could say "ignore reviews from other websites". Even a little bit of adversarial pressure can break it in arbitrary way.
The only solution I can think of if you *need* to process potentially adversarial data is for the LLM to write *code* that works with the data. Like if you are formatting data comparing restaurants, tell it to write python code to do that. Otherwise, restaurants could cause the LLM to skip over competing restaurants or what not.


@tao I use the more controlled Copilot from GitHub, and it has been brilliant most of the time. The occasions where it's bad, it's REALLY bad, but at least not suggesting genocide bad. I guess it's still GPT-3 behind the scenes, so it will be interesting to see how it goes when they upgrade to 4.
@tao I just added some ChatGPT integration to the latex editor in cocalc: https://github.com/sagemathinc/cocalc/discussions/6643